_Gated Recurrent Unit.jpg "واحد بازگشتی گیت دار")
واحد بازگشتی گیت دار
دسته : هوش مصنوعی
نویسنده : فاطمه تابع
تاریخ : 1403/1/25
سطح : پیشرفته
پست های مرتبط
_Time series Data.jpg)
دادههای سریزمانی
_Text Summarization.jpg)
خلاصهسازی متن با هوش...
_MatplotLib.jpg)
معرفی کتابخانه Matplotlib در...
_TensorFlow.jpg)
معرفی کتابخانه Tensorflow
_Pytorch.jpg)
معرفی کتابخانه PyTorch
_pandas.jpg)
کتابخانه Pandas همراه با کاربردها...
_Numerical Python.jpg)
آشنایی با کتابخانه NumPy...
_Intrusion Detection System.jpg)
سیستمهای تشخیص نفوذ
_Distributed Denial of Service.jpg)
حمله انکار از سرویس توزیع...
_DOS.jpg)
حملات انکار سرویس یا DOS...
_Text Mining.jpg)
متن کاوی چیست؟
_NLP.jpg)
پردازش زبان طبیعی چیست؟
واحد بازگشتی گیت دار
GRUها روش قدرتمند و کارآمدی برای پردازش دادههای ترتیبی (Time Series) ارائه میدهند. توانایی آنها در رسیدگی به وابستگیهای بلندمدت، آنها را به ابزارهای ارزشمندی برای کاربردهای مختلف در هوش مصنوعی تبدیل میکند.
در عرصه یادگیری عمیق، شبکههای عصبی بازگشتی (RNNs) به خاطر توانایی آنها در پردازش دادههای متوالی به بهترین شکل، همواره تحسین شدهاند. با این حال، RNNs سنتی محدودیتهایی دارند، بهویژه زمانی که به بررسی وابستگیهای بلندمدت در دنبالهها میپردازند. واحد بازگشتی گیت دار (GRUs)، نوعی معماری RNN است که برخی از این نقایص را برطرف میکند و همچنین بهبودهایی در عملکرد ارائه میدهد.
قبل از وارد شدن به GRU ها، مهم است که چالشهایی که RNN های سنتی با آنها مواجه هستند را درک کنیم. RNN های سنتی با مشکل گرادیان ناپدید شونده روبرو هستند، جایی که گرادیانها به صورت نمایی در حین انتشار به عقب (Back Propagation) در زمان در زمان آموزش کاهش مییابند. این پدیده توانایی مدل را در گرفتن وابستگیهای بلندمدت در دنبالهها را مختل میکند.
GRU توسط کیونگهیون چو و همکارانش در سال ۲۰۱۴ به عنوان راهحلی برای مشکل گرادیان ناپدید شونده با ارائه کارایی محاسباتی نسبتاً به واحدهای حافظه کوتاه مدت و طولانی (LSTM) به معرض دید گذاشته شدند. GRU مکانیسمهای دروازهای را در هر واحد مکرر دربرمیگیرند، که به آنها امکان میدهد جریان اطلاعات را در سراسر شبکه تنظیم کنند. این دروازهها کنترل میکنند که چقدر اطلاعات از یک زماننقطه به زماننقطه بعدی منتقل شود، که به بهبود مشکل گرادیان ناپدید شونده کمک میکند و امکان مدلسازی بهتری از وابستگیهای بلندمدت را فراهم میکند.
واحد GRU معمولی از چندین مؤلفه تشکیل شده است، هرکدام نقش مهمی در پردازش دادههای متوالی دارند:
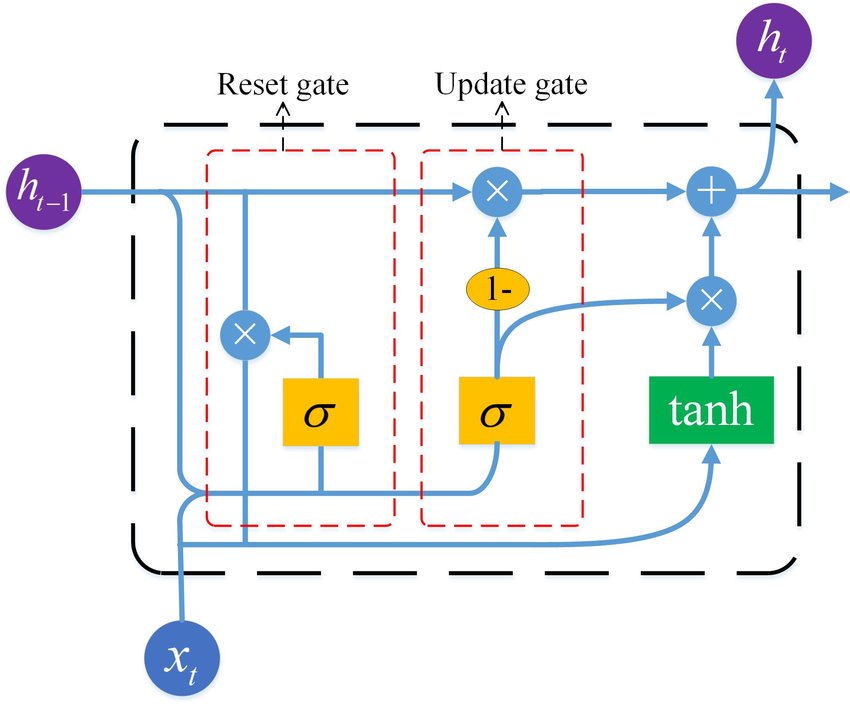
دروازه بهروزرسانی (Update Gate): دروازه بهروزرسانی تعیین میکند که چقدر از اطلاعات گذشته باید به آینده منتقل شود. این دروازه با در نظر گرفتن ورودی فعلی و اطلاعات از زمان نقطه قبلی، تصمیم میگیرد که کدام قسمتهای گذشته باید فراموش شوند و کدام باید بهروز شوند.
دروازه بازنشانی (Reset Gate): دروازه بازنشانی تعیین میکند که چقدر از اطلاعات گذشته مربوط به زمان فعلی است. این گیت کنترل میکند کدام اطلاعات گذشته باید در محاسبه وضعیت فعلی نادیده گرفته شود.
در ادامه چندین مزیت GRU را نسبت به RNN و LSTM بررسی می کنیم:
GRU ساختار سادهتری نسبت به LSTM دارد، که به زمان آموزش سریعتر و هزینه محاسباتی کمتری منجر میشود.
GRU نسبت به RNN سنتی کمتر به مشکل گرادیان ناپدید شونده برخورد می کند، که یادگیری آن را در وظایف مربوط به داده هایی که دنبالههای بلندتری دارند، آسانتر میکند.
واحد بازگشتی گیت دار یک وضعیت پنهان تکی دارد، برخلاف LSTM که حافظه سلول و وضعیت پنهان را جداگانه دارد. این باعث مصرف کمتر حافظه میشود که در محیطهای محدود حافظه مفید است.
GRU در موارد مختلفی استفاده می شود که در ادامه برخی از آن ها را بررسی می کنیم:
پردازش زبان طبیعی یا Natural Language Processing: به دلیل توانایی GRU در مدلسازی دادههای متوالی، در وظایفی مانند تحلیل احساسات، ترجمه ماشینی و تولید متن به کار میروند.
پیش بینی سری های زمانی: در پیشبینی ارزشهای آینده در دادههای سری زمانی عملکرد بسیار خوبی دارند که در کاربردهایی مانند پیشبینی بازار سهام، پیشبینی آب و هوا و تشخیص ناهنجاری ارزشمند هستند.
تشخیص گفتار (Speech Recognition): GRU در سیستمهای تشخیص سخن برای پردازش دنبالههای صوتی و استخراج ویژگیهای مربوطه برای تشریح دقیق بهکار میروند.
واحدهای بازگشتی گیت دار(GRUs) نشاندهنده پیشرفت مهمی در زمینه شبکههای عصبی بازگشتی هستند، که عملکرد و کارایی بهتری در پردازش دادههای متوالی ارائه میدهند. با گنجاندن مکانیسمهای دروازهای، GRUs در عین حفظ سادگی و کارایی محاسباتی نقصهای RNN سنتی را رفع میکنند.
پست های مرتبط
دادههای سریزمانی
خلاصهسازی متن با هوش...
معرفی کتابخانه Matplotlib در...
معرفی کتابخانه Tensorflow
معرفی کتابخانه PyTorch
کتابخانه Pandas همراه با کاربردها...
آشنایی با کتابخانه NumPy...
سیستمهای تشخیص نفوذ
حمله انکار از سرویس توزیع...
حملات انکار سرویس یا DOS...
متن کاوی چیست؟