_What is Supervised Learnong.jpg "یادگیری نظارت شده چیست و چه الگوریتم هایی در این دسته قرار دارند؟")
یادگیری نظارت شده چیست و چه الگوریتم هایی در این دسته قرار دارند؟
دسته : هوش مصنوعی
نویسنده : فاطمه تابع
تاریخ : 1402/8/13
سطح : پیشرفته
پست های مرتبط
_MatplotLib.jpg)
معرفی کتابخانه Matplotlib در...
_TensorFlow.jpg)
معرفی کتابخانه Tensorflow
_Pytorch.jpg)
معرفی کتابخانه PyTorch
_pandas.jpg)
کتابخانه Pandas همراه با کاربردها...
_Numerical Python.jpg)
آشنایی با کتابخانه NumPy...
_Intrusion Detection System.jpg)
سیستمهای تشخیص نفوذ
_Distributed Denial of Service.jpg)
حمله انکار از سرویس توزیع...
_DOS.jpg)
حملات انکار سرویس یا DOS...
_Text Mining.jpg)
متن کاوی چیست؟
_NLP.jpg)
پردازش زبان طبیعی چیست؟
_Sentiment Analysis.jpg)
تحلیل احساسات چیست و چه...
_Multi Layer Percepron.jpg)
شبکه عصبی پرسپترون چند...
یادگیری نظارت شده چیست و چه الگوریتم هایی در این دسته قرار دارند؟
یادگیری نظارت شده از یک مجموعه آموزشی دارای برچسب برای آموزش مدل ها، برای به دست آوردن خروجی مطلوب استفاده می کند.
در حوزهی یادگیری ماشین (Machine Learning)، از یادگیری نظارت شده به عنوان یکی روشهای بنیادی یاد می شود. در این روش، یک مدل بر اساس دادههای برچسبدار (Labeled) آموزش میبیند تا پیشبینیها را انجام داده و دادههای جدید یا نامعلوم را طبقهبندی کند. در این پست، به بررسی مفهوم یادگیری نظارت شده و بررسی الگوریتمهای محبوب مرتبط خواهیم پرداخت.
یادگیری نظارت شده چیست؟
یادگیری نظارت شده یک حوزه از یادگیری ماشین است که در آن مدل، از دادههای آموزشی برچسبدار برای پیشبینیها یا استنتاج الگوها استفاده میکند. عبارت "نظارت شده" به فرایند فراهم کردن یک ناظر یا معلم در قالب نمونههای برچسبدار اشاره دارد. این نمونههای برچسبدار شامل نقاط داده و خروجیهای مورد انتظار مربوط به آنها (برچسبها یا هدفها) هستند. هدف مدل، یادگیری یک تابع نگاشت است که بتواند خروجی را برای دادهی جدید و نامعلوم به صورت دقیق پیشبینی کند.
الگوریتمهای یادگیری نظارت شده:
چندین الگوریتم برای یادگیری نظارت شده توسعه داده شدهاند، هر کدام نقاط قوت، ضعف و حوزه کاربردی خاصی دارد. در ادامه، به برخی از الگوریتمهای یادگیری نظارت شده محبوب اشاره خواهیم کرد:
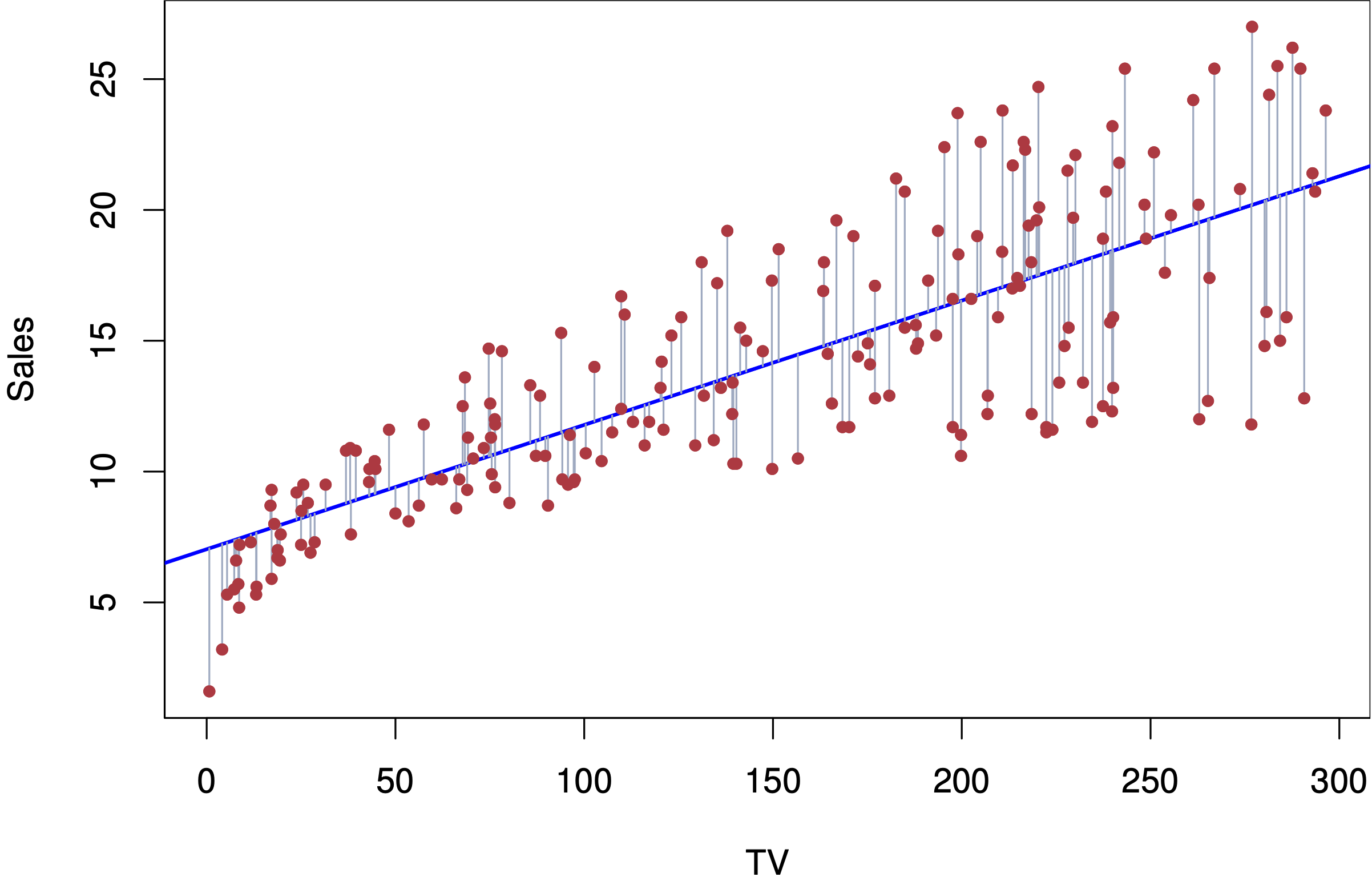
رگرسیون خطی (Linear Regression): این الگوریتم برای مدلسازی رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده میشود. هدف آن پیدا کردن خطی است که کمترین تفاوت بین، مقادیر پیشبینی شده و مقادیر واقعی را داشته باشد.
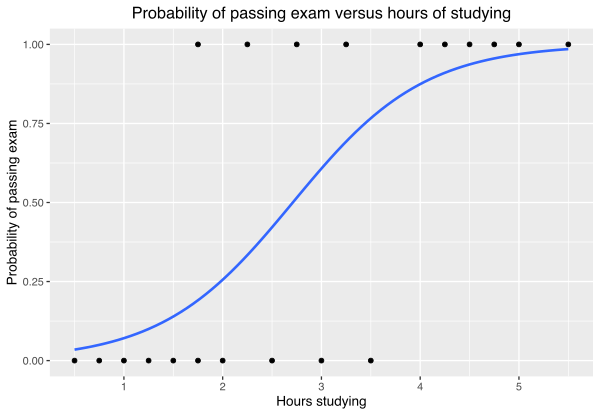
رگرسیون لجستیک (Logistic Regression): برخ خلاف رگرسیون خطی، رگرسیون لجستیک برای وظیفههای طبقهبندی دودویی استفاده میشود. این الگوریتم احتمال متعلق بودن یک نمونه، به یک کلاس خاص را محاسبه می کند. در اصل این الگوریتم با استفاده از تابع لجستیک برروی ترکیب خطی از ویژگیها کار می کند.
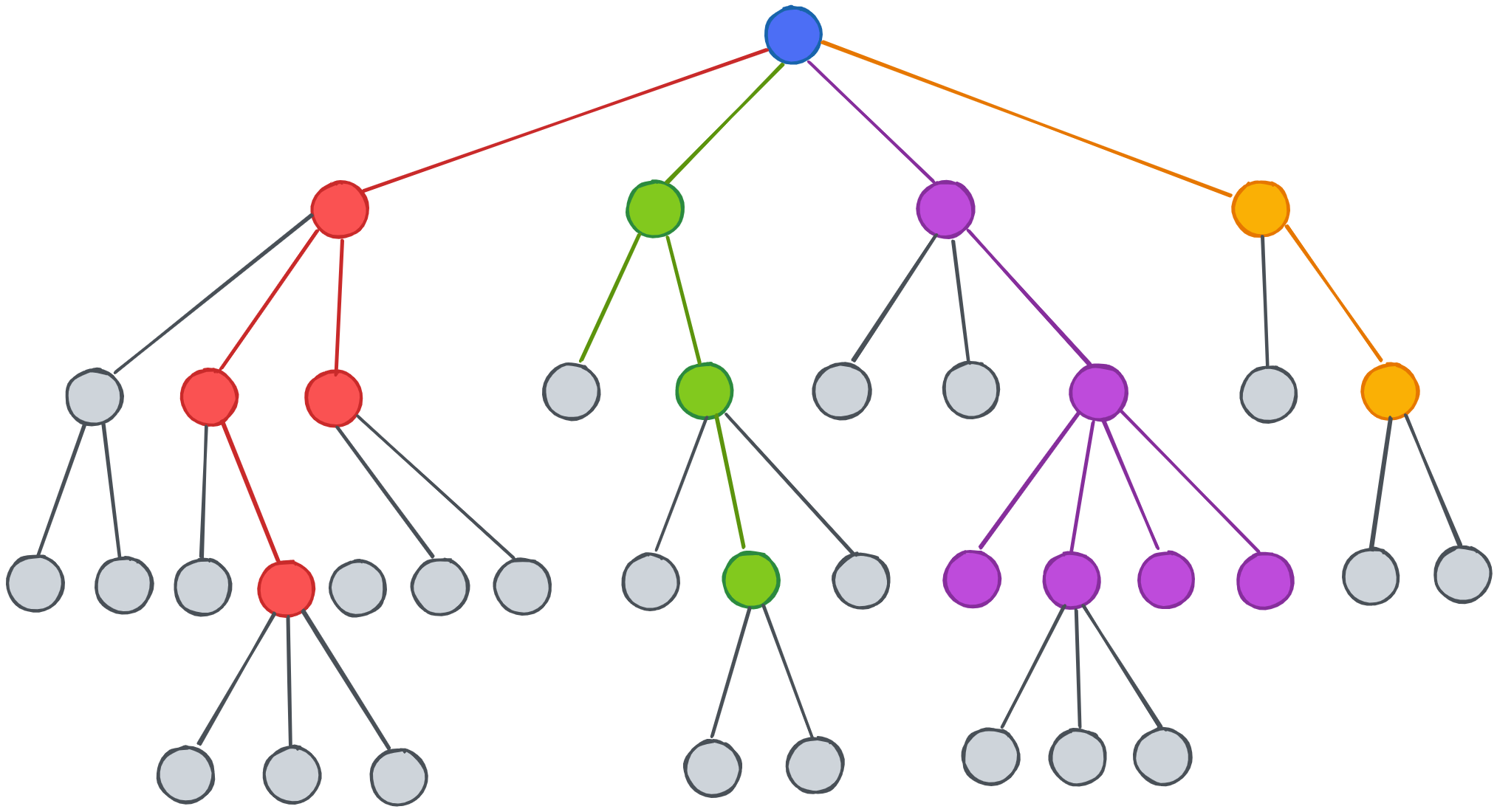
درخت تصمیم (Decision Tree): درختهای تصمیم، الگوریتمهای چندمنظورهای هستند که براساس ارزیابی ویژگیها، دادهها را به بخشهای مختلف تقسیمبندی میکنند و یک ساختار مانند درخت ایجاد میکنند. در اصل با عبور از درخت، بر اساس مقادیر ویژگیها برای داده ورودی، پیشبینی را انجام میدهند.
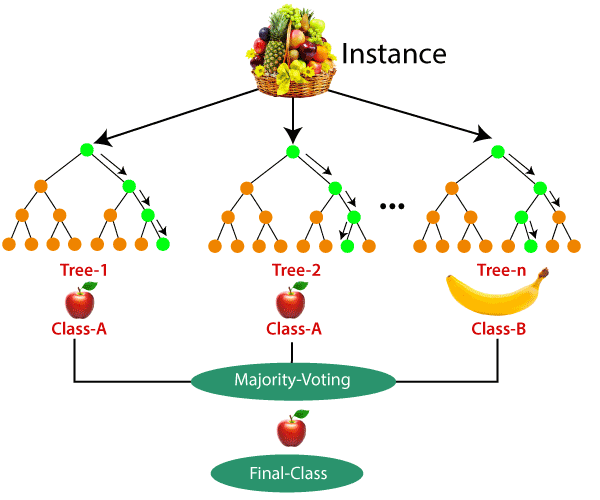
جنگل تصادفی (Random Forest): جنگل تصادفی یک روش ترکیبی است که مجموعه ای از چند درخت تصمیم را برای پیشبینی استفاده میکند. هر درخت روی یک دسته نمونه تصادفی از داده، آموزش داده می شود و پیشبینی نهایی، با جمعبندی پیشبینیهای درختها انجام میشود.
ماشینهای بردار پشتیبان (Support Vector Machines): ماشینهای بردار پشتیبان به دنبال یافتن یک ابرصفحه (Hyperplane) است که بهترین تفکیک را بین کلاسهای مختلف ایجاد کند. آنها حاشیه بین کلاسها را بیشینه میکنند و با استفاده از توابع هسته (Kernel)، میتوانند وظایف طبقهبندی خطی و غیرخطی را انجام دهند.
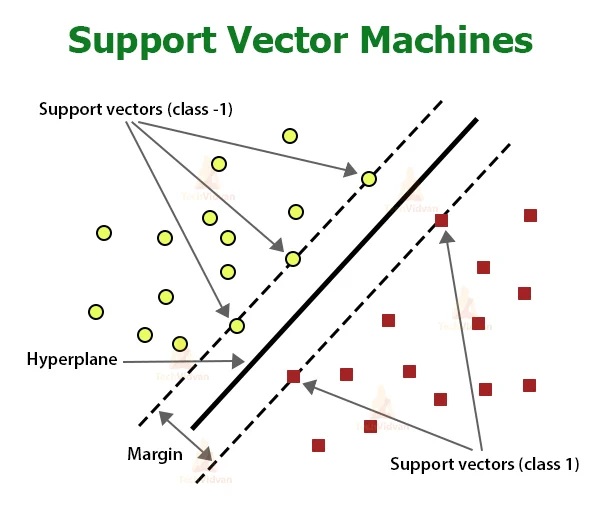
نایو بیز (Nive Bayes): الگوریتمهای Nive Bayes بر اساس قضیه بیز و فرض استقلال بین ویژگیها توسعه یافته است. آنها برای طبقهبندی متن و سایر وظایف، با فضای ویژگیهای بالا کارآمد هستند.
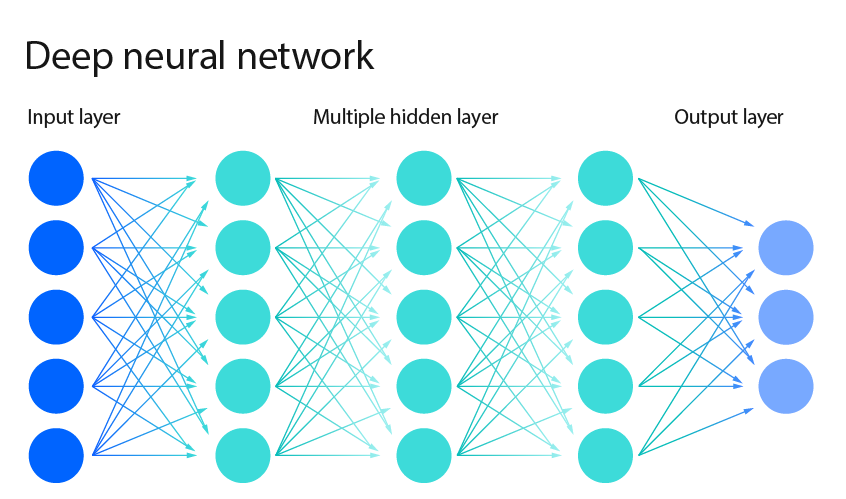
شبکههای عصبی (Neural Networks): شبکههای عصبی، به ویژه مدلهای یادگیری عمیق (Deep Learning)، در سالهای اخیر به طور قابل توجهی محبوبیت کسب کردهاند. آنها از لایههای متصل از نورونهای مصنوعی تشکیل شده اند. آنها میتوانند به مسائل پیچیده مانند تشخیص تصویر، پردازش زبان طبیعی و تشخیص گفتار پرداخته و پاسخ مناسبی را ارائه دهند.
تحلیل نمونهها و نمونههای نماینده:
یکی از عوامل مهم در یادگیری نظارت شده، انتخاب نمونههای مناسب برای آموزش است. نمونههایی که از تنوع و جزئیات مورد نیاز در دادهها برخوردار باشند، به مدل کمک میکنند تا الگوهای قویتری را استخراج کرده و پیشبینیهای دقیقتری ارائه دهد.
تحلیل نمونهها به معنای بررسی و تفسیر دقیق دادههای آموزشی است. این فرآیند شامل بررسی ویژگیهای مختلف نمونهها، شناخت الگوها و روابط بین ویژگیها، شناسایی دادههای نویزی یا نامتعادل و تشخیص نمونههای نماینده است. نمونههای نماینده نقش مهمی در یادگیری دارند زیرا میتوانند نمایندههای خوبی از دادهها باشند و به مدل کمک کنند که الگوهای عمومی را درک کند و از برازش زیاد (Overfit) به دادههای نویزی جلوگیری کند.
تحلیل نمونهها میتواند به روشهای مختلف صورت گیرد. برخی از روشهای معمول شامل موارد زیر است:
تجزیه و تحلیل ویژگیها: در این روش، ویژگیهای مختلف موجود در دادهها بررسی میشوند و تأثیر آنها در پیشبینی مدل موردنظر بررسی میشود. میتوان با بررسی ویژگیها و ارزیابی اهمیت آنها، ویژگیهای بیاهمیت را حذف کرد و مدل را بهینه کرد.
کاوش دادههای نامتعادل: در بعضی موارد، دادههای آموزشی ممکن است نامتعادل باشند، به این معنی که تعداد نمونههای یک کلاس نسبت به کلاسهای دیگر، بسیار بیشتر یا کمتر باشد. در این صورت، تحلیل و تصحیح نامتعادلی دادهها میتواند بهبود عملکرد مدل را به دنبال داشته باشد.
تشخیص پشتیبانی مدل: هنگام تحلیل نمونهها، میتوان از خروجیهای مدل برای ارزیابی عملکرد آن استفاده کرد. با مشاهده پیشبینیهای مدل بر روی نمونههای آموزشی، میتوان نظریههایی درباره قواعد و الگوهایی که مدل درک کرده، استخراج کرد. این اطلاعات میتوانند در بهبود مدل و افزایش دقت آن مورد استفاده قرار بگیرند.
تحلیل خطا: بررسی خطاهای مدل و تحلیل دقیق دلایل آنها میتواند راهنمایی برای بهبود مدل باشد. با تشخیص الگوهای خطا و علت آنها، میتوان تغییراتی در معماری مدل، تنظیمات آموزش یا دادههای آموزشی اعمال کرد تا خطاها کاهش یابند.
به طور کلی، تحلیل نمونهها در یادگیری میتواند بهبود عملکرد مدل و درک بهتری از دادهها و ویژگیهای آنها فراهم کند. با استفاده از روشهای تحلیل مختلف و بهرهگیری از دانش و تجربههای کسب شده، میتوان مدل را بهبود داد و درک عمیقتری از دادهها و مسائل مورد نظر پیدا کرد.
الگوریتمهای یادگیری نظارت شده نقش حیاتی در حل یک مجموعه گسترده از مسائل واقعی دارند. آنها از دادههای برچسبدار برای یادگیری الگوها و انجام پیشبینی بر روی نمونههای ناشناخته استفاده میکنند. درک الگوریتمهای مختلف و ویژگیهای آنها، افراد را قادر میسازد تا رویکرد مناسب را برای وظایف خاص انتخاب کنند. علاوه بر این، توجه دقیق به کیفیت، اندازه، تعادل و نمایندگی نمونهها برای دستیابی به پیشبینی دقیق و قابل اعتماد بسیار حائز اهمیت است. با فراگیری اصول و تکنیکهای یادگیری نظارت شده، میتوانیم پتانسیل یادگیری ماشین را در حوزههای مختلف به کار ببریم و به پیشرفتهای زیادی در فناوری و جامعه دست یابیم.
پست های مرتبط
معرفی کتابخانه Matplotlib در...
معرفی کتابخانه Tensorflow
معرفی کتابخانه PyTorch
کتابخانه Pandas همراه با کاربردها...
آشنایی با کتابخانه NumPy...
سیستمهای تشخیص نفوذ
حمله انکار از سرویس توزیع...
حملات انکار سرویس یا DOS...
متن کاوی چیست؟
پردازش زبان طبیعی چیست؟
تحلیل احساسات چیست و چه...