_Machine LaerningPic.jpg "یادگیری ماشین چیست؟")
یادگیری ماشین چیست؟
دسته : هوش مصنوعی
نویسنده : فاطمه تابع
تاریخ : 1401/5/25
تعداد لایک : 2
سطح : متوسط
پست های مرتبط
_Text Summarization.jpg)
خلاصهسازی متن با هوش...
_MatplotLib.jpg)
معرفی کتابخانه Matplotlib در...
_TensorFlow.jpg)
معرفی کتابخانه Tensorflow
_Pytorch.jpg)
معرفی کتابخانه PyTorch
_pandas.jpg)
کتابخانه Pandas همراه با کاربردها...
_Numerical Python.jpg)
آشنایی با کتابخانه NumPy...
_Intrusion Detection System.jpg)
سیستمهای تشخیص نفوذ
_Distributed Denial of Service.jpg)
حمله انکار از سرویس توزیع...
_DOS.jpg)
حملات انکار سرویس یا DOS...
_Text Mining.jpg)
متن کاوی چیست؟
_NLP.jpg)
پردازش زبان طبیعی چیست؟
_Sentiment Analysis.jpg)
تحلیل احساسات چیست و چه...
یادگیری ماشین چیست؟
یادگیری ماشین یا Machine Learning (به اختصار ML)، زیرمجموعهای از هوش مصنوعی (Artificial Intelligence) است. در یادگیری ماشین با داده هایی (Data) قبلی و الگوریتم هایی که درون خودش دارد، انتخاب می کند که در این زمان چه کاری را انجام دهد.
یادگیری ماشین یا Machine Learning (به اختصار ML)، زیرمجموعهای از هوش مصنوعی (Artificial Intelligence) است که بر تجزیه، تحلیل و تفسیر الگوها و ساختار دادهها تمرکز دارد. به زبان ساده، Machine Learning این امکان را فراهم میکند تا ماشین، بدون این که دقیقا برای کاری برنامه نویسی شود، بتواند تصمیم به انجام آن کار بگیرد و آن را انجام دهد. یعنی با داده هایی (Data) که از قبل به ماشین داده شده و الگوریتم هایی که درون خودش دارد، انتخاب می کند که در این زمان چه کاری را انجام دهد. در اصل در Machine Learning یادگیری انسان شبیه سازی می شود و به تدریج دقت خودش را بالا و بالاتر می برد. همانطور که گفتیم یادگیری ماشین زیر مجموعه ای از هوش مصنوعی است و هوش مصنوعی هم دقیقا تلاش دارد تا مغز انسان را شبیه سازی کند.

در الگوریتم های Machine Learning سعی شده که سیستم کاملا شبیه به انسان عمل کند. یعنی از تجربیات گذشته خود استفاده می کند و همچنین با دیدن داده های جدید، الگوریتم یاد بگیرد و در تصمیمات خود در صورت نیاز، تغییر ایجاد می کند. لازم به ذکر است که تمام این فرایند بدون دخالت انسان انجام شده و تنها یک بار کد نویسی انجام می شود.
مفهوم یادگیری ماشین (Machine Learning) ابتدا در سال ،1950 توسط آلن تورینگ در مقاله ‘آیا ماشین ها می توانند فکر کنند؟’ مطرح شد. همچنین در سال 1957 اولین شبکه عصبی که امروزه به آن مدل پرسپترون میگویند، توسط فرانک روزنبلات مطرح شد. در سال 1962 یکی از کارمندان شرکت IBM در بازی (checkers) به کامپیوتر باخت و آنجا بود که کم کم همه چیز به صورت جدی شروع به پیشرفت کرد. الگوریتم Nearest Neighbor هم در سال 1967 نوشته شد که برای تشخیص الگو های ابتدایی بود.
در طول دهه 90 میلادی، کار بر روی یادگیری ماشین (ML) بیشتر به سمت داده محور شدن حرکت کرد و دانشمندان سعی کردند برنامه هایی را برای رایانه ها بنویسند که حجم داده های بیشتر را تجزیه و تحلیل کنند. هدف یادگیری ماشین (ML) این است که هوش مصنوعی سریع تر پیشرفت کند و نتایج بهتری در وظایف خود داشته باشند، پس این تکنولوژی جدید می تواند تاثیرات چشمگیری در زندگی انسان داشته باشد. اخیرا ML پیشرفت های زیادی داشته است از جمله دسترسی سریع به داده های بسیار زیاد و متنوع (Big Data)، ذخیره سازی اطلاعات بیشتر با هزینه کمتر، افزایش قدرت پردازش کامپیوتر ها که منجر به محاسبات بیشتر در زمان کمتر شده و... . با این تفاسیر یادگیری ماشین بهبود چشمگیری یافته است و در اکثر کسب و کار ها و صنعت ها وارد شده است.
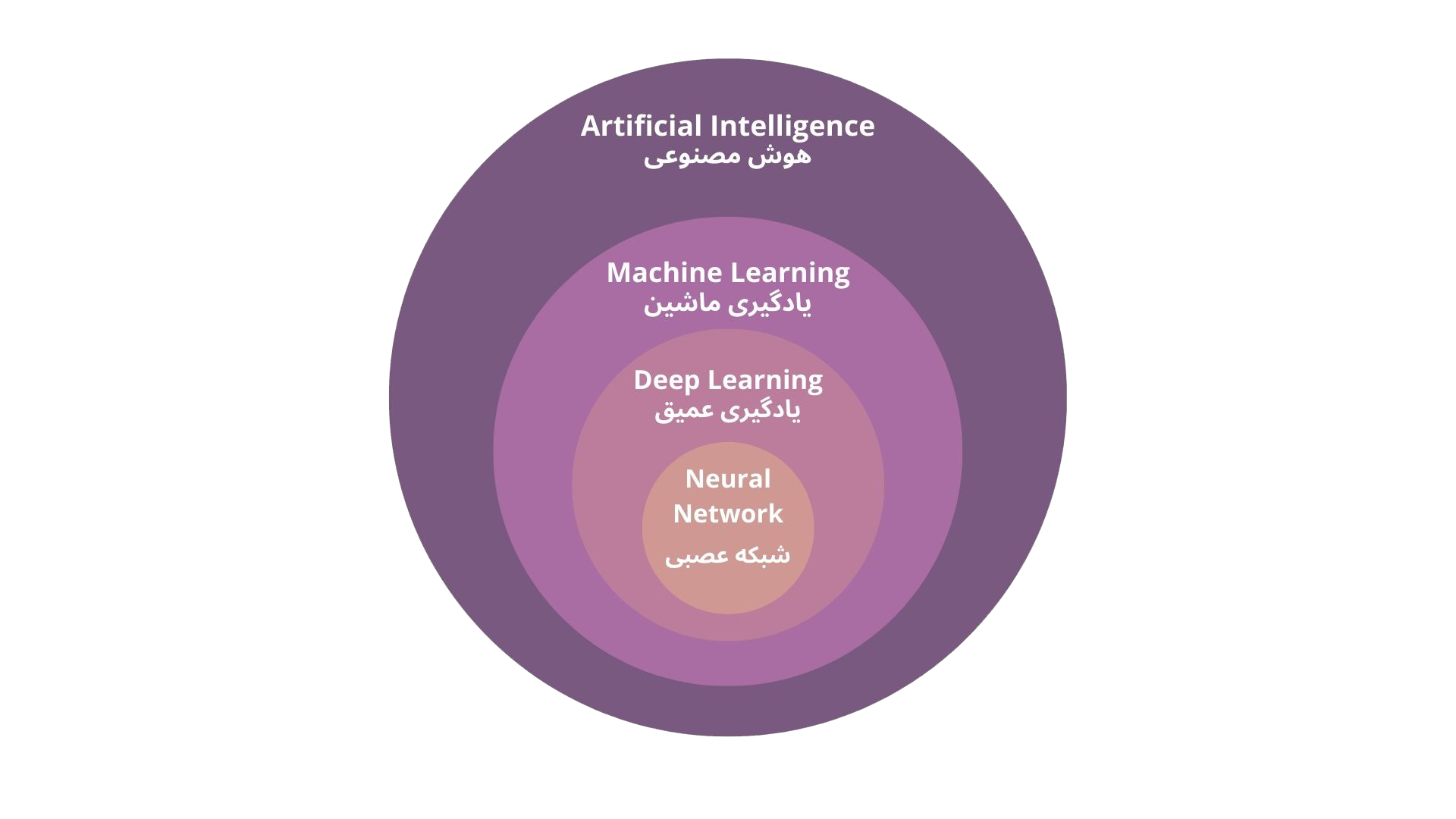
گاهی دیده شده که یادگیری ماشین (Machine Learning) و یادگیری عمیق (Deep Learning) به جای یکدیگر استفاده شده است اما تفاوت های بسیاری دارند. به صورت کلی می توان گفت که یادگیری عمیق، فرایند استخراج ویژگی را به صورت خودکار انجام می دهد. با شکل زیر به صورت خلاصه مرز این دو علم را متوجه خواهید شد. در پست های بعدی حتما به بررسی یادگیری عمیق (DL) خواهیم پرداخت.
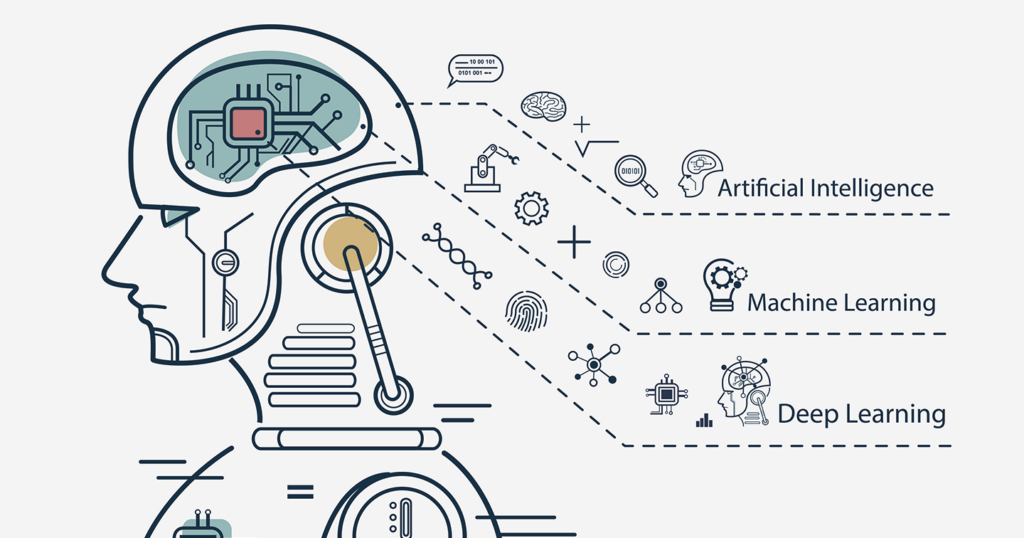
الگوریتم یادگیری ماشین (Machine Learning) سه بخش اصلی دارد:
· فرآیند تصمیم گیری: (Decision Process) تصمیم گیری الگوریتم درباره الگو داده های ورودی.
· تابع خطا : (Error Function) مدلی که الگوریتم می سازد باید ارزیابی شود تا مقدار دقت و خطا آن مشخص شود.
· فرآیند بهینه سازی مدل: (Model Optimization Process) بعد از اندازه گیری خطا، مدل با داده های آموزشی خودش را بهبود می دهد و طبق تکرار یادگیری و ارزیابی ها، باعث بیشتر شدن دقت مدل می شود.
الگوریتم های یادگیری ماشین را می توان به 4 دسته کلی تقسیم کرد:
1. یادگیری تحت نظارت یا نظارت شده (Supervised learning):
در این الگوریتم، داده های ما دارای Class یا Label هستند و یا اصطلاحا نشانه گذاری شده اند و ما می دانیم در کدام دسته قرار دارند. در این حالت ماشین از روی یک سری داده آموزشی، مدلی را می سازد. بعد از اتمام این فاز که به فاز یادگیری یا Train شناخته می شود، می توان داده ای را بدون Label به الگوریتم داده تا برای ما کلاسش را پیش بینی کند. درست یا غلط بودن پیش بینی بستگی به دقت مدل Train شده دارد. روش هایی که در این مدل یادگیری استفاده می شود شامل neural networks، naïve bayes، linear regression و support vector machine (SVM) و ... هستند.
2. یادگیری بدون نظارت یا نظارت نشده (Unsupervised learning):
در این مدل الگوریتم، داده های ما نشانه گذاری و دسته بندی نشده اند یعنی Class و Label ندارند. در این روش ما، اصطلاحا داده ها را خوشه بندی می کنیم. یعنی داده هایی که به یکدیگر شباهت دارند را در یک خوشه قرار می دهیم. از این الگوریتم ها برای پیدا کردن الگو های مخفی در بین داده ها استفاده می شود. روش های متداول در این مدل یادگیری Neural Networks و K-Means Clustering و ... هستند.
3. یادگیری نیمه نظارت شده (Semi-supervised learning):
این مدل یادگیری ترکیبی از دو روش بالا است. یعنی داده های ما هم شامل Class هستند و هم نیستند. در این روش دقت مدل آموزش دیده شده تا حد زیادی بالاتر می رود.
4. یادگیری تقویت شده (Reinforcement learning):
این مدل یادگیری مشابه یادگیری نظارت شده است، با این تفاوت که در مرحله Train به جای این که مدل داده های آماده را ببیند، با استفاده از پاداش و مجازات (آزمون و خطا) خودش را بهبود می دهد. یعنی با محیط اطراف خودش تعامل برقرار می کند. در این روش پاداش مشخص می شود اما نحوه روبرویی با مشکلات و حل مسئله به مدل داده نمی شود و خودش طبق داده ها و نتایج، درستی فرضیه که در مراحل قبل بدست آورده را بررسی می کند.

ما در زندگی روزمره بار ها از ماشین لرنینگ (ML) استفاده کرده ایم و این امر در همه جا وجود دارد. به طور مثال یکی از رایج ترین کاربرد های یادگیری ماشین، تشخیص تصویر یا چهره است. از کاربرد های دیگر Machine Learning می توان به موتورهای توصیهگر، فیلتر اسپم ایمیل، تشخیص کلاهبرداری، تشخیص خودکار گفتار، تشخیص بیماریها و مدیریت ارتباط با مشتری (CRM) اشاره کرد.
همانطور که گفته شد یادگیری ماشین علمی بسیار گسترده و داغ است که یکی از زیر مجموعه های هوش مصنوعی است و از موضوعاتی است که امروزه، مقاله های علمی زیادی درباره آن منتشر می شود. بر خلاف باور عمومی که تصور می کنند با هوش مصنوعی و ماشینی شدن کار ها دیگر شغلی برای انسان ها نیست، باید گفت که این حرف اساسا درست نیست. همانطور که مصرف سوخت، از فسیلی به برقی منتقل شد، اکنون هم وقت آن است که نوع شغل ها عوض شوند و کار انسان ها از انجام خود عملیات، به نظارت بر انجام عمل تبدیل شود.
امیدوارم که از پست اطلاعات مفیدی دریافت کرده باشید. ممنون که تا اینجا همراه ما بودید. منتظر نظرات ارزشمند شما هستیم.
پست های مرتبط
خلاصهسازی متن با هوش...
معرفی کتابخانه Matplotlib در...
معرفی کتابخانه Tensorflow
معرفی کتابخانه PyTorch
کتابخانه Pandas همراه با کاربردها...
آشنایی با کتابخانه NumPy...
سیستمهای تشخیص نفوذ
حمله انکار از سرویس توزیع...
حملات انکار سرویس یا DOS...
متن کاوی چیست؟
پردازش زبان طبیعی چیست؟